Deep Learning for Credit Card Fraud Detection
Comparing supervised, unsupervised, and hybrid models on the ULB dataset — with drift analysis and SHAP interpretability.
Abstract
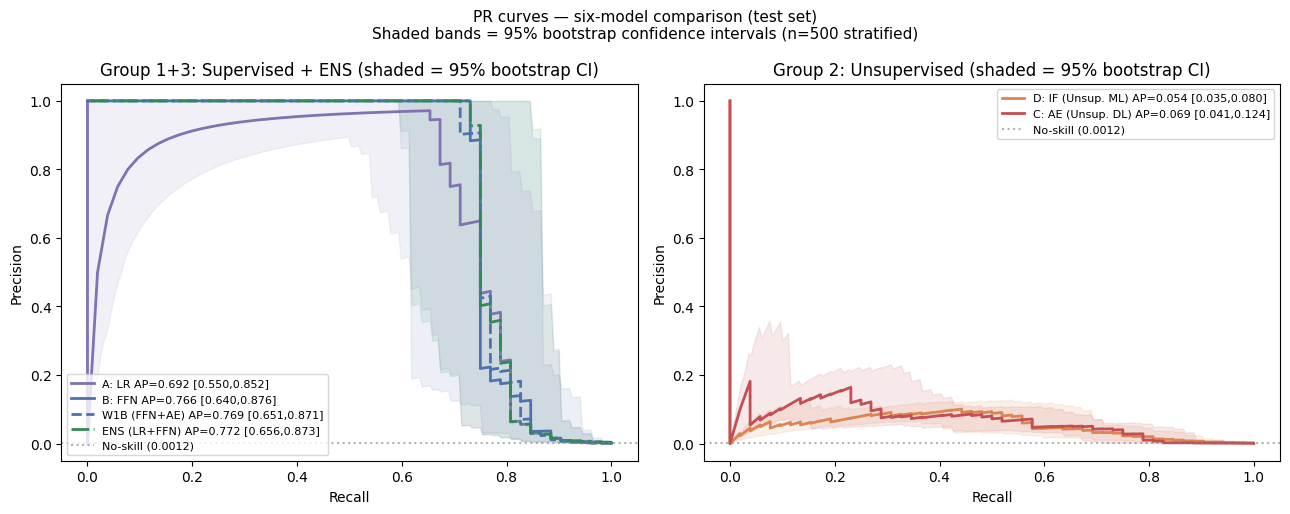
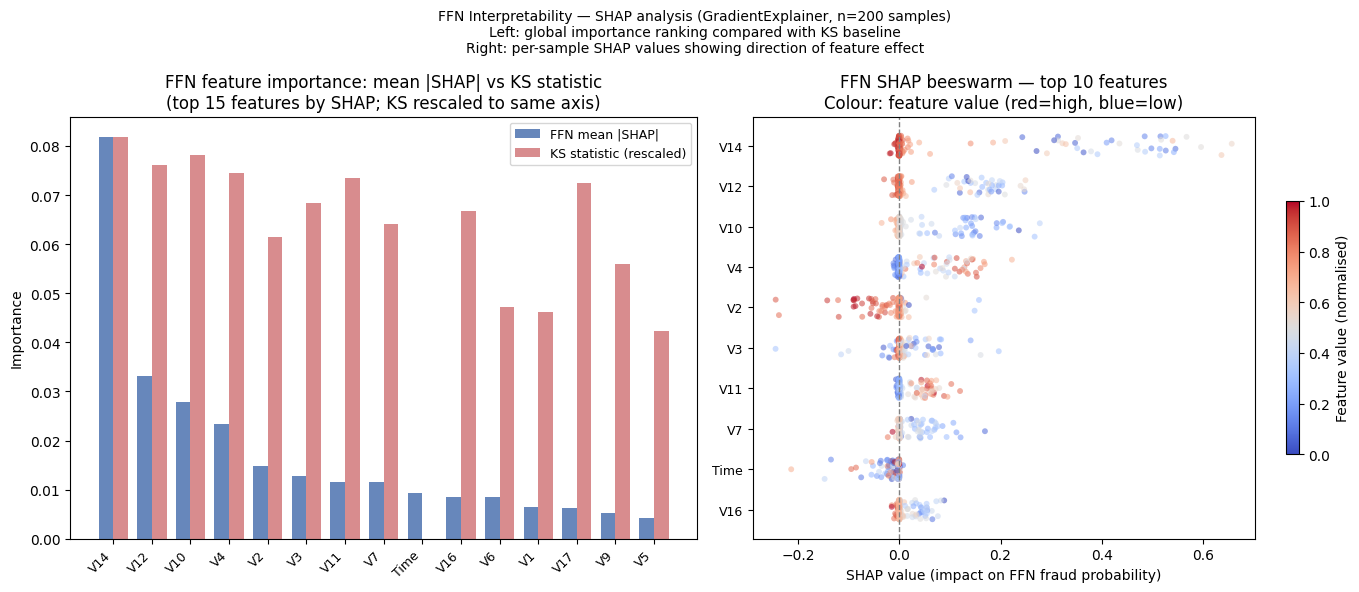
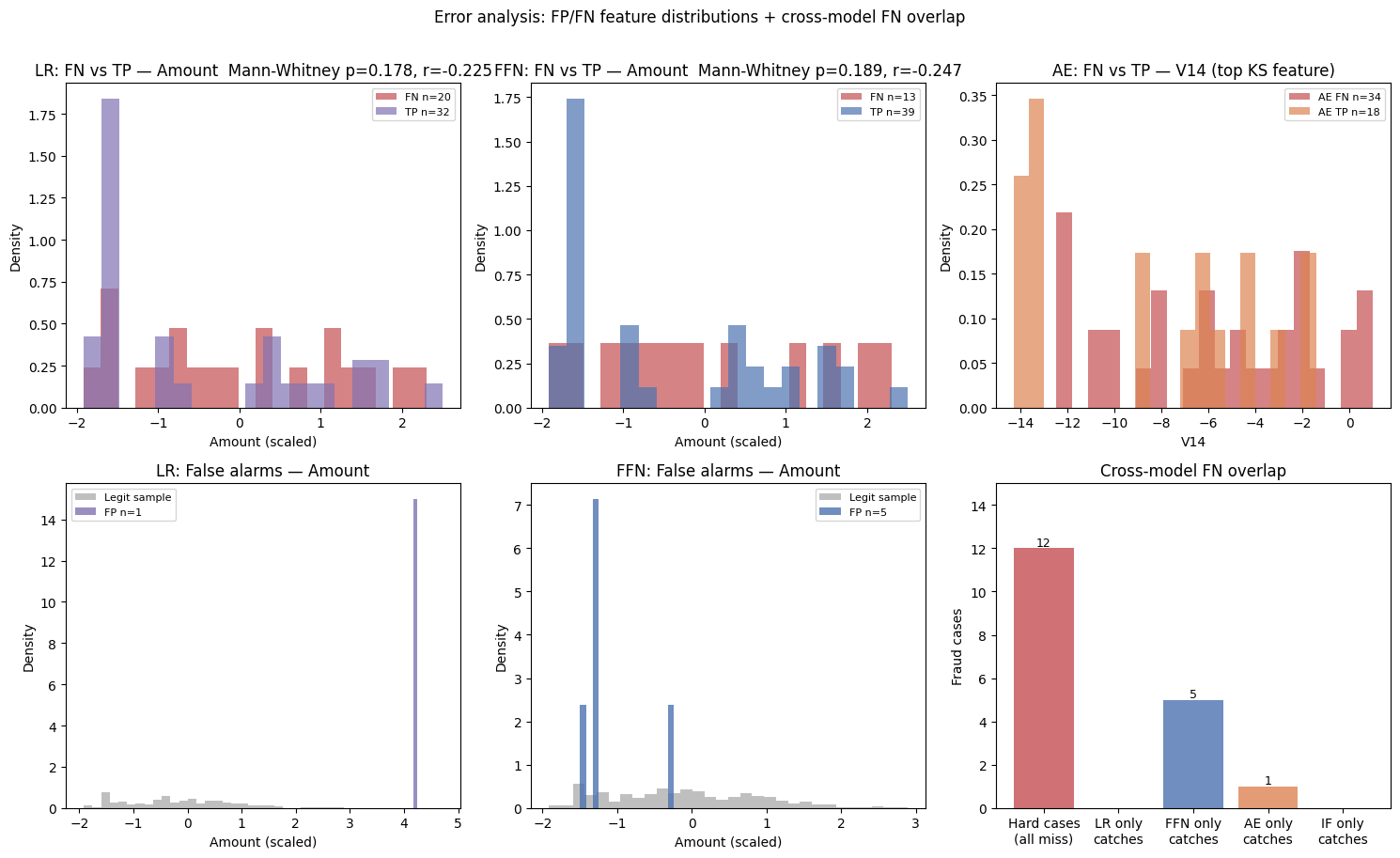
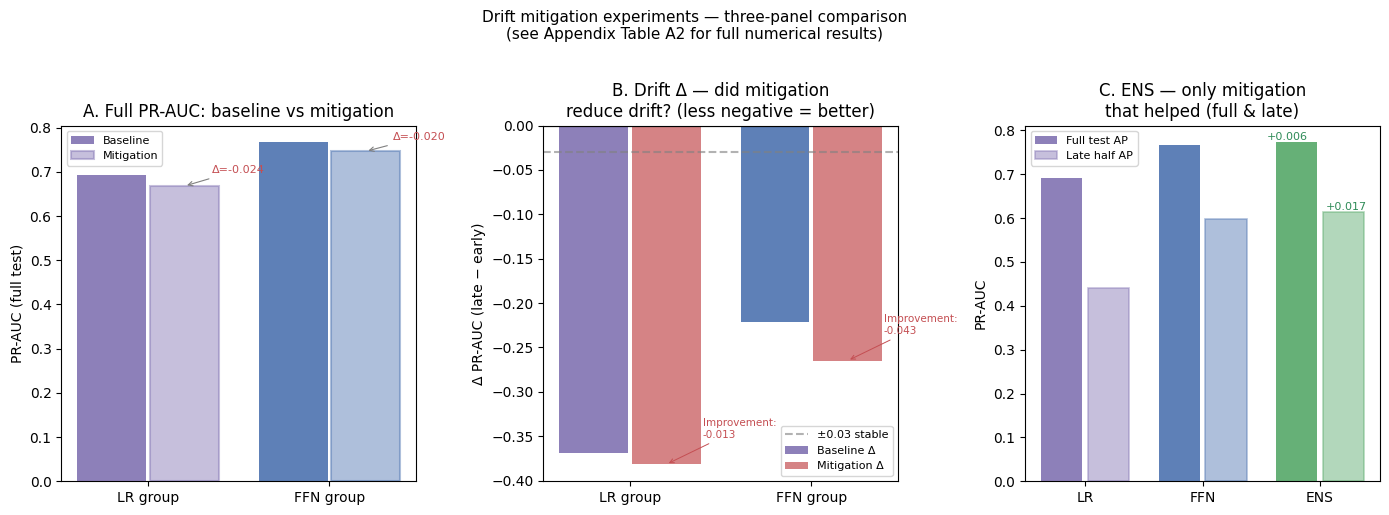
Payment card fraud across the European Economic Area reached EUR 4.2 billion in 2024. This project evaluates six model configurations on the ULB dataset — logistic regression, feed-forward network, isolation forest, autoencoder, and two hybrid extensions — under a strict chronological split that simulates deployment conditions. PR-AUC is adopted as the primary metric given extreme class imbalance (1:578). The FFN model (PR-AUC 0.766) remains statistically indistinguishable from logistic regression (McNemar's p = 0.58), while the LR+FFN ensemble pushes PR-AUC further to 0.772 — suggesting deep learning's advantages are operational rather than purely predictive. The project also simulates a production MLOps lifecycle — a versioned model registry with CI/CD promotion gates, PSI-based drift monitoring, and a champion/challenger canary rollout with statistical rollback — and benchmarks federated (FedAvg) against centralized and incremental retraining strategies.
Video
Live Demo
Interactive fraud detection system — submit a transaction to see the risk score, model decision, and SHAP feature breakdown in real time.
Highlights
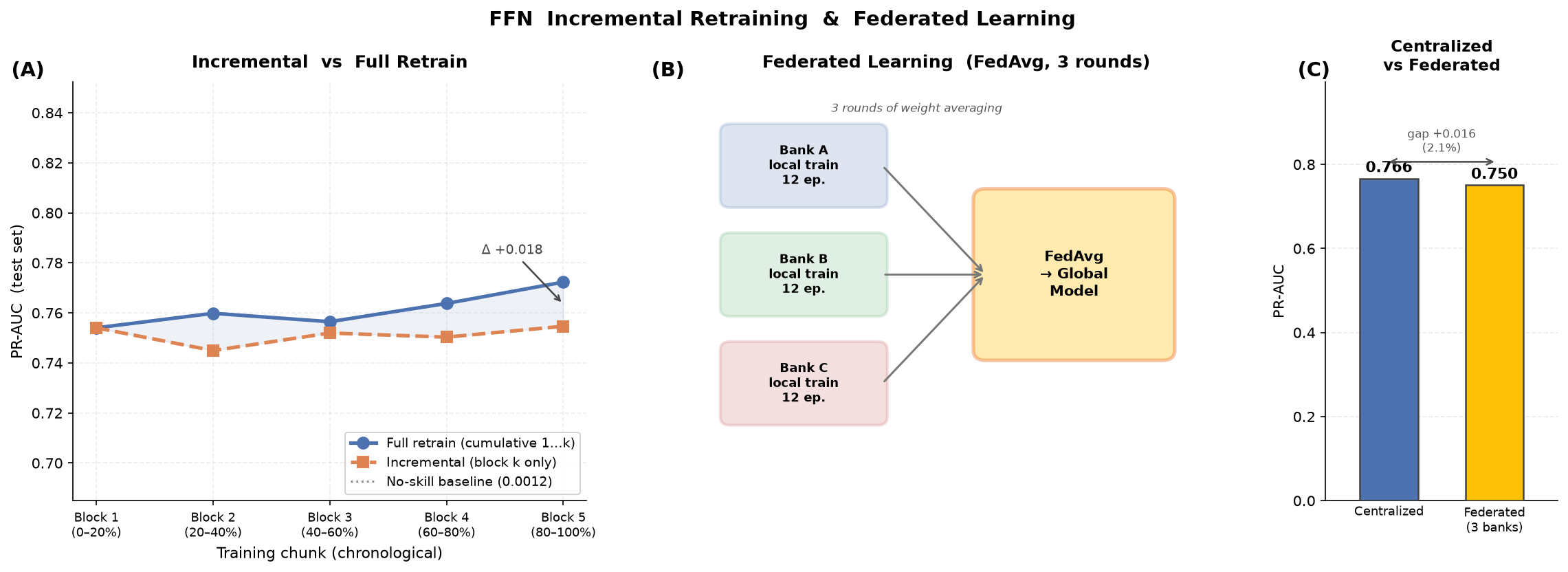
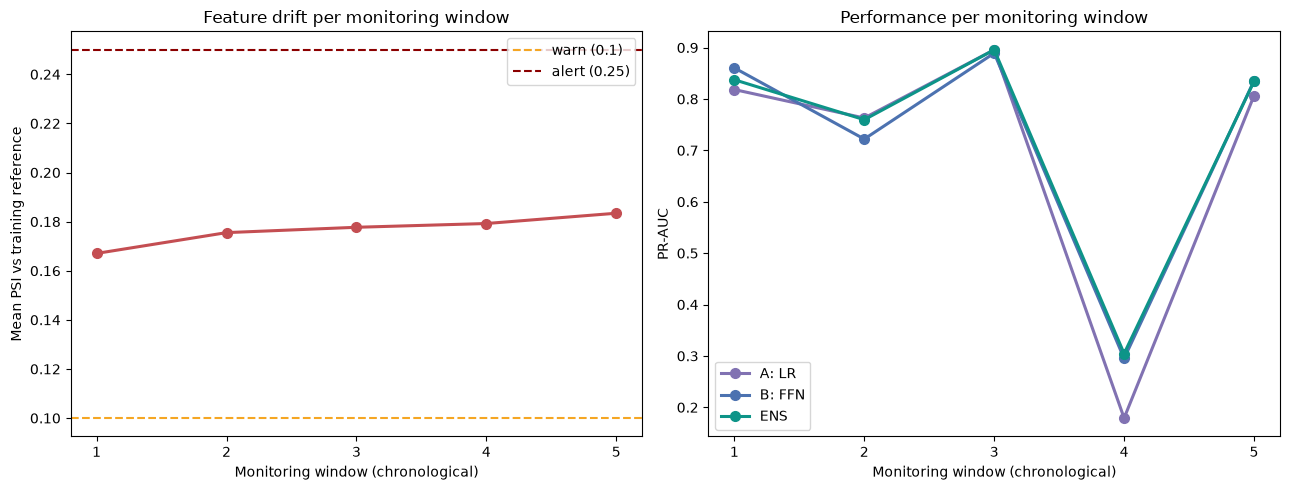
Results
| Model | Paradigm | PR-AUC | F1 | Recall@P=0.9 |
|---|---|---|---|---|
| LR | Supervised ML | 0.692 | 0.753 | 0.673 |
| FFN | Supervised DL | 0.766 | 0.813 | 0.731 |
| IF | Unsupervised ML | 0.054 | 0.133 | 0.000 |
| AE | Unsupervised DL | 0.069 | 0.129 | 0.000 |
| W1B | Semi-supervised | 0.770 | 0.821 | 0.750 |
| ENS | Ensemble | 0.772 | 0.821 | 0.750 |
Test set: n = 42,722, 52 fraud cases. Threshold targets Precision ≥ 0.90.
Read More
Full analysis with all 18 figures, drift experiments, and SHAP deep-dive:
Read the analysis note →